Apache Hadoop Fedora 27 Install
How to Install Apache Hadoop on Fedora 27 GNU/Linux desktop – Step by step Tutorial.
Especially relevant: this guide shows an Apache Hadoop Vanilla Installation in Pseudo-Distributed mode on Fedora 27.
First, Hadoop is a distributed master-slave that consists of the Hadoop Distributed File System (HDFS) for storage and Map-Reduce for computational capabilities.
And Hadoop Distributed File System (HDFS) is a distributed file system that spreads data blocks across the storage defined for the Hadoop cluster.
Moreover, the foundation of Hadoop is the two core frameworks YARN and HDFS. These two frameworks deal with Processing and Storage.
The Apache Hadoop Setup Require an Oracle JDK 8+ Installation on System.
Finally, this guide includes detailed instructions about to Getting Started with Hadoop.

-
First, Open a Shell Terminal emulator window
(Press “Enter” to Execute Commands)
In case first see: Terminal Quick Start Guide.
-
Download Latest Apache Hadoop Stable Release:
-
Then Extract Into /tmp Directory
Double-Click on Archive:
Or from Shell:
tar xvzf *hadoop*tar.gz -C /tmp
-
And Relocate Apache Hadoop Directory
Get SuperUser Privileges (This simply to make shorter the command’s series):sudo su
If Got “User is Not in Sudoers file” then see: How to Enable sudo
Then Switch the contents with:mv /tmp/hadoop* /usr/local/
Furthermore, make an hadoop symlink directory:
ln -s /usr/local/hadoop* /usr/local/hadoop
-
Make Hadoop Needed Directories:
First, Make the Logs Dir:
mkdir /usr/local/hadoop/logs
Giving Writing Permissions:
chmod 777 /usr/local/hadoop/logs
Next Make the Cache Dir:
mkdir /usr/local/hadoop/cache
Same Writing Permissions as for Logs:
chmod 777 /usr/local/hadoop/cache
And then also the Temporary Dir:
mkdir /usr/local/hadoop/tmp
And Set the root as Owner:
sudo chown -R root:root /usr/local/hadoop*
-
How to Install Required Java JDK 8+ on Fedora
-
Set JAVA_HOME in Hadoop Env File
First, Make the Conf directory:mkdir /usr/local/hadoop/conf
And then Make an Env file:
nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh
So now Append:
export JAVA_HOME=[oracleJdkPath]
Change [oracleJdkPath] with the current Version:
Ctrl+x to Save & Exit from nano Editor :) -
Setup Hadoop Configuration for Pseudo-Distributed mode
nano /usr/local/hadoop/conf/core-site.xml
And Append:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:8020</value> </property> </configuration>
Next:
nano /usr/local/hadoop/conf/hdfs-site.xml
And Append:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <!-- NameNode data directory --> <name>dfs.name.dir</name> <value>/usr/local/hadoop/cache/hadoop/dfs/name</value> </property> <property> <!-- DataNode data directory --> <name>dfs.data.dir</name> <value>/usr/local/hadoop/cache/hadoop/dfs/data</value> </property> </configuration>
Next Make the Log4j Configuration:
nano /usr/local/hadoop/conf/log4j.properties
Simply Click and Drag Down to Select & Right-Click Copy, finally Append into:
# Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. you may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Define some default values that can be overridden by system properties hadoop.root.logger=INFO,console hadoop.log.dir=. hadoop.log.file=hadoop.log # Define the root logger to the system property "hadoop.root.logger". log4j.rootLogger=${hadoop.root.logger}, EventCounter # Logging Threshold log4j.threshold=ALL # Null Appender log4j.appender.NullAppender=org.apache.log4j.varia.NullAppender # # Rolling File Appender - cap space usage at 5gb. # hadoop.log.maxfilesize=256MB hadoop.log.maxbackupindex=20 log4j.appender.RFA=org.apache.log4j.RollingFileAppender log4j.appender.RFA.File=${hadoop.log.dir}/${hadoop.log.file} log4j.appender.RFA.MaxFileSize=${hadoop.log.maxfilesize} log4j.appender.RFA.MaxBackupIndex=${hadoop.log.maxbackupindex} log4j.appender.RFA.layout=org.apache.log4j.PatternLayout # Pattern format: Date LogLevel LoggerName LogMessage log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n # Debugging Pattern format #log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n # # Daily Rolling File Appender # log4j.appender.DRFA=org.apache.log4j.DailyRollingFileAppender log4j.appender.DRFA.File=${hadoop.log.dir}/${hadoop.log.file} # Rollover at midnight log4j.appender.DRFA.DatePattern=.yyyy-MM-dd log4j.appender.DRFA.layout=org.apache.log4j.PatternLayout # Pattern format: Date LogLevel LoggerName LogMessage log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n # Debugging Pattern format #log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n # # console # Add "console" to rootlogger above if you want to use this # log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n # # TaskLog Appender # #Default values hadoop.tasklog.taskid=null hadoop.tasklog.iscleanup=false hadoop.tasklog.noKeepSplits=4 hadoop.tasklog.totalLogFileSize=100 hadoop.tasklog.purgeLogSplits=true hadoop.tasklog.logsRetainHours=12 log4j.appender.TLA=org.apache.hadoop.mapred.TaskLogAppender log4j.appender.TLA.taskId=${hadoop.tasklog.taskid} log4j.appender.TLA.isCleanup=${hadoop.tasklog.iscleanup} log4j.appender.TLA.totalLogFileSize=${hadoop.tasklog.totalLogFileSize} log4j.appender.TLA.layout=org.apache.log4j.PatternLayout log4j.appender.TLA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n # # HDFS block state change log from block manager # # Uncomment the following to suppress normal block state change # messages from BlockManager in NameNode. #log4j.logger.BlockStateChange=WARN # #Security appender # hadoop.security.logger=INFO,NullAppender hadoop.security.log.maxfilesize=256MB hadoop.security.log.maxbackupindex=20 log4j.category.SecurityLogger=${hadoop.security.logger} hadoop.security.log.file=SecurityAuth-${user.name}.audit log4j.appender.RFAS=org.apache.log4j.RollingFileAppender log4j.appender.RFAS.File=${hadoop.log.dir}/${hadoop.security.log.file} log4j.appender.RFAS.layout=org.apache.log4j.PatternLayout log4j.appender.RFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n log4j.appender.RFAS.MaxFileSize=${hadoop.security.log.maxfilesize} log4j.appender.RFAS.MaxBackupIndex=${hadoop.security.log.maxbackupindex} # # Daily Rolling Security appender # log4j.appender.DRFAS=org.apache.log4j.DailyRollingFileAppender log4j.appender.DRFAS.File=${hadoop.log.dir}/${hadoop.security.log.file} log4j.appender.DRFAS.layout=org.apache.log4j.PatternLayout log4j.appender.DRFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n log4j.appender.DRFAS.DatePattern=.yyyy-MM-dd # # hadoop configuration logging # # Uncomment the following line to turn off configuration deprecation warnings. # log4j.logger.org.apache.hadoop.conf.Configuration.deprecation=WARN # # hdfs audit logging # hdfs.audit.logger=INFO,NullAppender hdfs.audit.log.maxfilesize=256MB hdfs.audit.log.maxbackupindex=20 log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=${hdfs.audit.logger} log4j.additivity.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=false log4j.appender.RFAAUDIT=org.apache.log4j.RollingFileAppender log4j.appender.RFAAUDIT.File=${hadoop.log.dir}/hdfs-audit.log log4j.appender.RFAAUDIT.layout=org.apache.log4j.PatternLayout log4j.appender.RFAAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n log4j.appender.RFAAUDIT.MaxFileSize=${hdfs.audit.log.maxfilesize} log4j.appender.RFAAUDIT.MaxBackupIndex=${hdfs.audit.log.maxbackupindex} # # mapred audit logging # mapred.audit.logger=INFO,NullAppender mapred.audit.log.maxfilesize=256MB mapred.audit.log.maxbackupindex=20 log4j.logger.org.apache.hadoop.mapred.AuditLogger=${mapred.audit.logger} log4j.additivity.org.apache.hadoop.mapred.AuditLogger=false log4j.appender.MRAUDIT=org.apache.log4j.RollingFileAppender log4j.appender.MRAUDIT.File=${hadoop.log.dir}/mapred-audit.log log4j.appender.MRAUDIT.layout=org.apache.log4j.PatternLayout log4j.appender.MRAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n log4j.appender.MRAUDIT.MaxFileSize=${mapred.audit.log.maxfilesize} log4j.appender.MRAUDIT.MaxBackupIndex=${mapred.audit.log.maxbackupindex} # Custom Logging levels #log4j.logger.org.apache.hadoop.mapred.JobTracker=DEBUG #log4j.logger.org.apache.hadoop.mapred.TaskTracker=DEBUG #log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=DEBUG # Jets3t library log4j.logger.org.jets3t.service.impl.rest.httpclient.RestS3Service=ERROR # AWS SDK & S3A File System log4j.logger.com.amazonaws=ERROR log4j.logger.com.amazonaws.http.AmazonHttpClient=ERROR log4j.logger.org.apache.hadoop.fs.s3a.S3AFileSystem=WARN # # Event Counter Appender # Sends counts of logging messages at different severity levels to Hadoop Metrics. # #log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter # # Job Summary Appender # # Use following logger to send summary to separate file defined by # hadoop.mapreduce.jobsummary.log.file : # hadoop.mapreduce.jobsummary.logger=INFO,JSA # hadoop.mapreduce.jobsummary.logger=${hadoop.root.logger} hadoop.mapreduce.jobsummary.log.file=hadoop-mapreduce.jobsummary.log hadoop.mapreduce.jobsummary.log.maxfilesize=256MB hadoop.mapreduce.jobsummary.log.maxbackupindex=20 log4j.appender.JSA=org.apache.log4j.RollingFileAppender log4j.appender.JSA.File=${hadoop.log.dir}/${hadoop.mapreduce.jobsummary.log.file} log4j.appender.JSA.MaxFileSize=${hadoop.mapreduce.jobsummary.log.maxfilesize} log4j.appender.JSA.MaxBackupIndex=${hadoop.mapreduce.jobsummary.log.maxbackupindex} log4j.appender.JSA.layout=org.apache.log4j.PatternLayout log4j.appender.JSA.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n log4j.logger.org.apache.hadoop.mapred.JobInProgress$JobSummary=${hadoop.mapreduce.jobsummary.logger} log4j.additivity.org.apache.hadoop.mapred.JobInProgress$JobSummary=false # # Yarn ResourceManager Application Summary Log # # Set the ResourceManager summary log filename yarn.server.resourcemanager.appsummary.log.file=rm-appsummary.log # Set the ResourceManager summary log level and appender yarn.server.resourcemanager.appsummary.logger=${hadoop.root.logger} #yarn.server.resourcemanager.appsummary.logger=INFO,RMSUMMARY # To enable AppSummaryLogging for the RM, # set yarn.server.resourcemanager.appsummary.logger to #,RMSUMMARY in hadoop-env.sh # Appender for ResourceManager Application Summary Log # Requires the following properties to be set # - hadoop.log.dir (Hadoop Log directory) # - yarn.server.resourcemanager.appsummary.log.file (resource manager app summary log filename) # - yarn.server.resourcemanager.appsummary.logger (resource manager app summary log level and appender) log4j.logger.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=${yarn.server.resourcemanager.appsummary.logger} log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=false log4j.appender.RMSUMMARY=org.apache.log4j.RollingFileAppender log4j.appender.RMSUMMARY.File=${hadoop.log.dir}/${yarn.server.resourcemanager.appsummary.log.file} log4j.appender.RMSUMMARY.MaxFileSize=256MB log4j.appender.RMSUMMARY.MaxBackupIndex=20 log4j.appender.RMSUMMARY.layout=org.apache.log4j.PatternLayout log4j.appender.RMSUMMARY.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n Last:
nano /usr/local/hadoop/conf/mapred-site.xml
And Append:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:8021</value> </property> </configuration>
-
Again SetUp Local Path & Environment
Exit from SuperUser to the normal User:exit
Then Change to the Home directory:
cd
And Edit the bash Config file:
nano .bashrc
So Inserts:
HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME=/usr/lib/jvm/<oracleJdkVersion>
Replace <oracleJdkVersion> with the Correct JDK Release you can find running:
update-alternatives --config java
And for the Java Compiler instead:
sudo update-alternatives --config javac
But Skip this if already Made JAVA_HOME Setup during JDK Installation…
Finally, to Load the New Setup simply:bash
-
Follow to SetUp Needed Local SSH Connection.
sudo systemctl start ssh
Generate SSH Keys to Access:
ssh-keygen -b 2048 -t rsa
echo "$(cat ~/.ssh/id_rsa.pub)" > ~/.ssh/authorized_keys
Testing Connection:
ssh 127.0.0.1
-
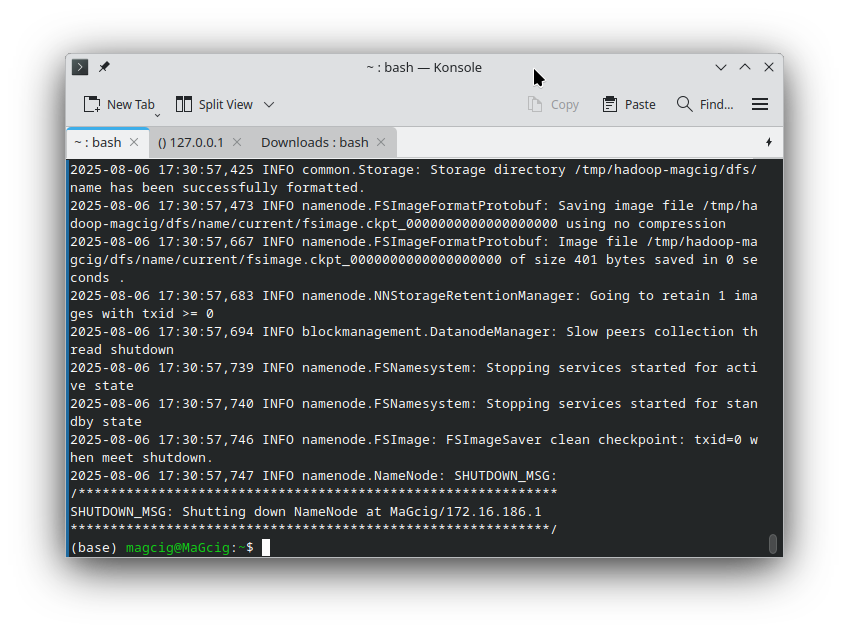
Moreover, to Format the HDFS.
hdfs namenode -format
-
Finally, to Start Up Hadoop Database.
start-all.sh
-
Apache Hadoop Database Quick Start Guide
Hadoop MapReduce Quick Start
Eclipse Hadoop Integration with Free Plugin.