Getting Started
-
10. Setting Up SSH
Follow to Set Up the Required Local SSH Connection
Start and Enable the SSH Service:sudo systemctl enable --now ssh
Generate SSH Keys for Local Access:
ssh-keygen -b 2048 -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
chmod 700 ~/.ssh
Testing the SSH Connection:
ssh -o "StrictHostKeyChecking=no" 127.0.0.1
-
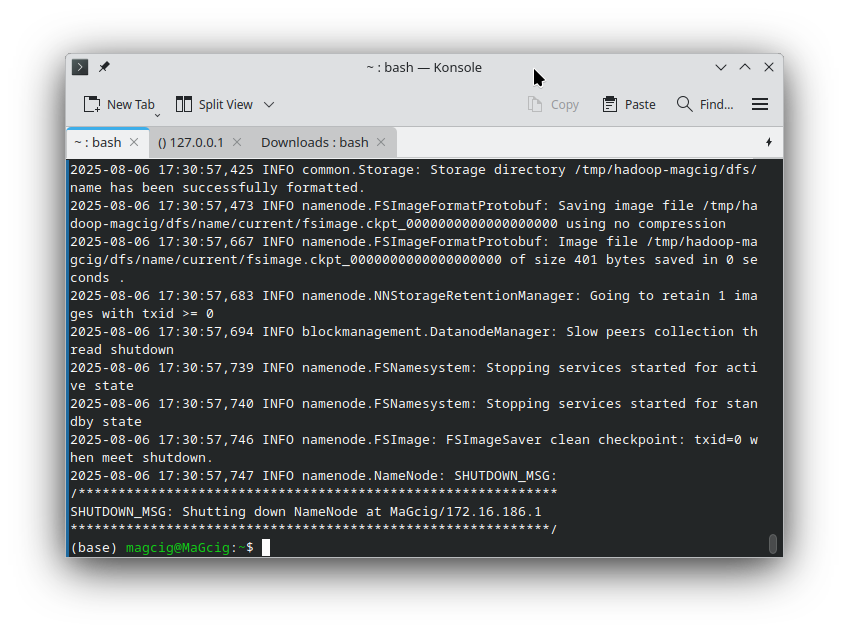
11. Formatting HDFS File System
Moreover, to Format the HDFS
Run:hdfs namenode -format
-
12. Starting Up Hadoop
Finally, to Start Up Hadoop Services
Execute:start-dfs.sh
start-yarn.sh
And then to check they are running:
jsp
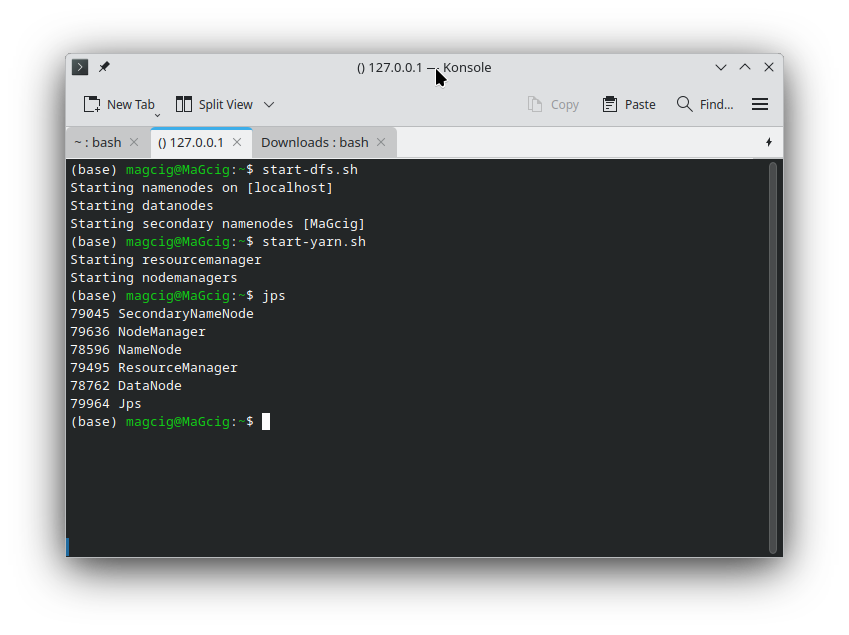
In the output you should see the started Nodes and Managers:
- DataNode
- NameNode
- SecondaryNameNode
- NodeManager
- ResourceManager
-
13. Hadoop Getting Started
Apache Hadoop Database Getting Started Guide
Hadoop MapReduce Quick Start
Contents